Author: Paiteams AI Lab Engineering Team
Introduction: The "Context Rot" Dilemma
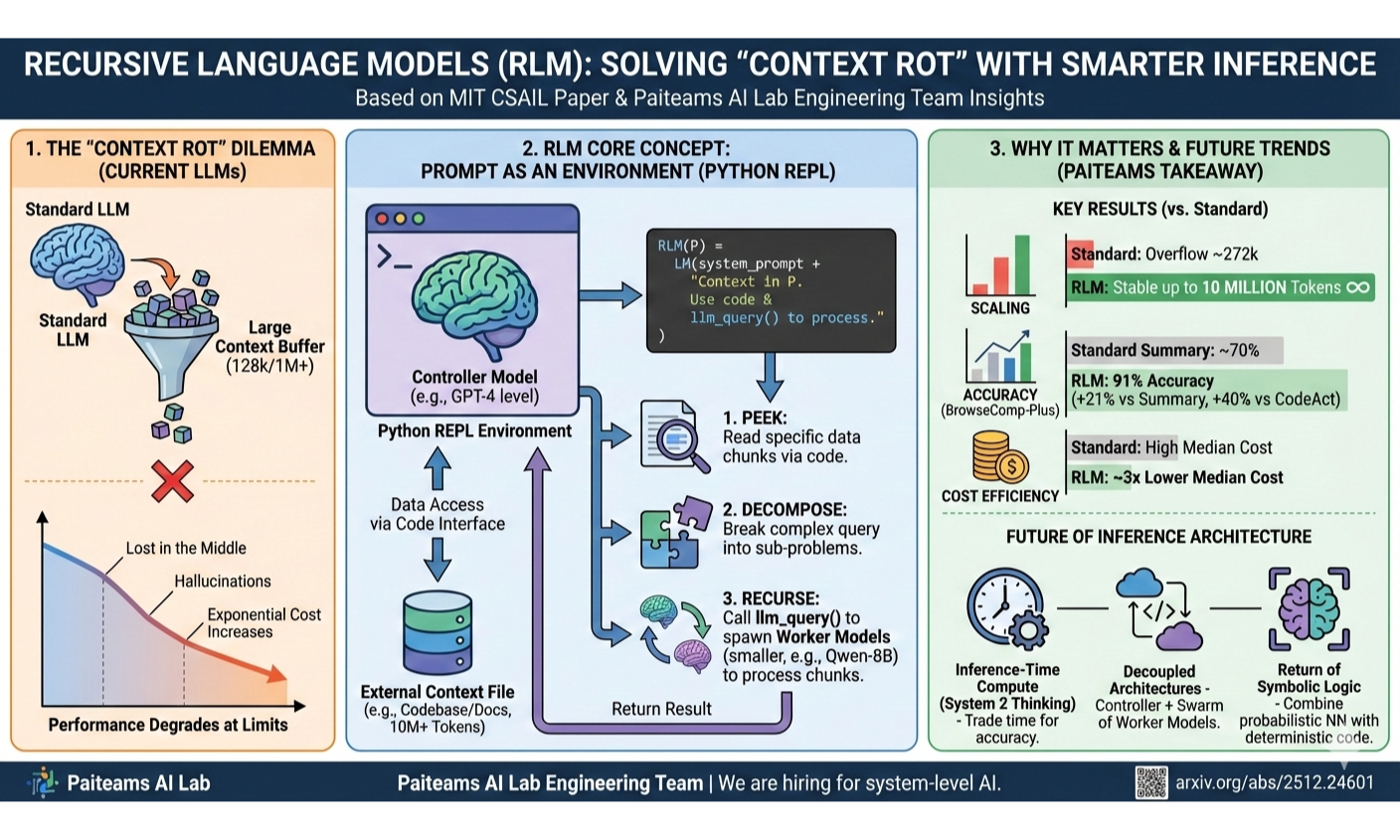
At Paiteams AI Lab, we are constantly pushing the boundaries of what Large Language Models (LLMs) can handle in production. A recurring challenge we face—and one that plagues the entire industry—is the "Context Rot" phenomenon.
While model providers advertise 128k, 1M, or even larger context windows, the reality of engineering is stark: as you approach these limits, performance degrades precipitously. Inputting a codebase or a mountain of legal documents often leads to "lost in the middle" errors, hallucinations, and exponential cost increases.
Recently, a paper from MIT CSAIL titled "Recursive Language Models (RLM)" caught our attention. It proposes a paradigm shift that aligns perfectly with our engineering philosophy: Don't just make the model bigger; make the inference smarter.
The Core Concept: Prompt as an Environment
The prevailing approach to long-context tasks is "filling the buffer"—stuffing as many tokens as possible into the Transformer's input. RLM takes a First Principles approach to challenge this.
Instead of feeding the text directly into the model, RLM treats the context as an external file residing in a Python REPL (Read-Eval-Print Loop) environment. The model is then tasked not with "reading" everything at once, but with writing code to explore the data.
The formula is elegant in its simplicity:
RLM(P) = LM(system_prompt + "Context stored in P. Use code and llm_query() to process.")
The model can:
- Peek: Read specific chunks of data using Python.
- Decompose: Break a complex query into sub-problems.
- Recurse: Call
llm_query()to spawn a sub-model (often a smaller, cheaper model like Qwen-8B) to process a specific chunk and return the result.
This transforms the LLM from a passive reader into an active agent running a recursive algorithm.
Why This Matters: 10 Million Tokens and Beyond
The experimental results presented in the paper are significant for anyone building AI SaaS:
- Infinite Scaling: RLM demonstrated stability up to 10 million tokens. For context, GPT-5's physical window (in the paper's tests) overflowed at around 272k.
- Accuracy: On complex retrieval tasks like BrowseComp-Plus, RLM achieved 91% accuracy, outperforming standard summary agents by 21% and CodeAct baselines by 40%.
- Cost Efficiency: By offloading sub-tasks to smaller models and only reading what is necessary, the median cost was approximately 3x lower than standard summarization methods.
Our Takeaway: The Future of Inference
At Paiteams, we believe RLM signals three key trends for the future of AI architecture:
- Inference-Time Compute: The future isn't just about training larger models; it's about spending more compute cycles during inference (System 2 thinking). RLM essentially trades time (recursion) for accuracy and infinite context.
- Decoupled Architectures: We are moving away from monolithic model calls. The winning architecture will likely be a "Controller Model" (GPT-4/5 level) orchestrating a swarm of "Worker Models" (7B/8B level) via code.
- The Return of Symbolic Logic: By embedding the LLM inside a REPL, we combine the probabilistic power of neural networks with the deterministic reliability of code execution.
Conclusion
The "Recursive Language Model" is more than just a paper; it is a blueprint for solving the long-context problem without waiting for the next generation of GPUs.
We are actively experimenting with these patterns at Paiteams AI Lab to bring "infinite context" capabilities to our users—reliably and affordably.
If you are an engineer passionate about system-level AI, recursive inference, and breaking the limits of LLMs, we are hiring. Join us in building the next generation of AI SaaS.